Engineering Fundamentals
Computer Science basics #
Архитектура компьютера #
Junior #
Что такое принцип фон Неймана (фоннеймановская архитектура)?
|
Программа и данные хранятся в общей памяти, а процессор читает и выполняет инструкции последовательно, если управление не изменено переходом. Классическая модель включает память, устройство управления, арифметико-логическое устройство и ввод/вывод. Главные принципы:
|
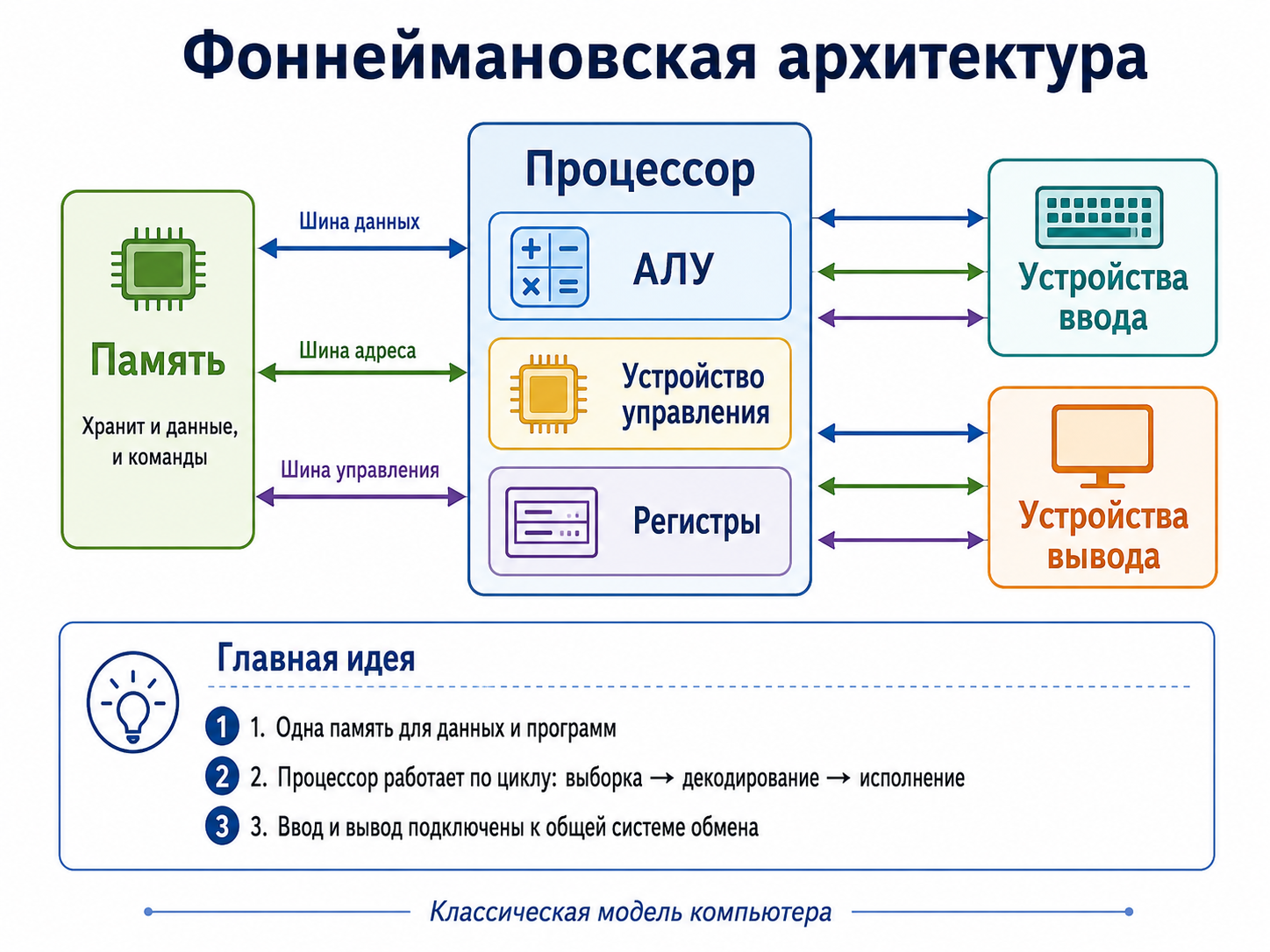
Из каких основных частей состоит компьютер по архитектуре фон Неймана?
|
Основные части:
CPU объединяет управление и вычисления, RAM хранит активные инструкции и данные, а ввод/вывод связывает программу с внешним миром. Современные компьютеры сложнее, но эта модель полезна как базовая абстракция. Строго говоря, CU + ALU ≠ CPU: это важные части процессора, но не весь процессор целиком. Помимо устройства управления (CU) и арифметико‑логического устройства (ALU), в современном CPU есть и другие критически важные компоненты:
На уровне базовой архитектуры (учебники, фон Нейман): часто говорят «CPU = CU + ALU», потому что цель — показать самую суть: есть тот, кто управляет (CU), и тот, кто считает (ALU). Это упрощение, удобное для понимания принципов. На уровне реального современного процессора: CPU — это сложная система из десятков и сотен подблоков, где CU и ALU — важные, но не единственные части. |
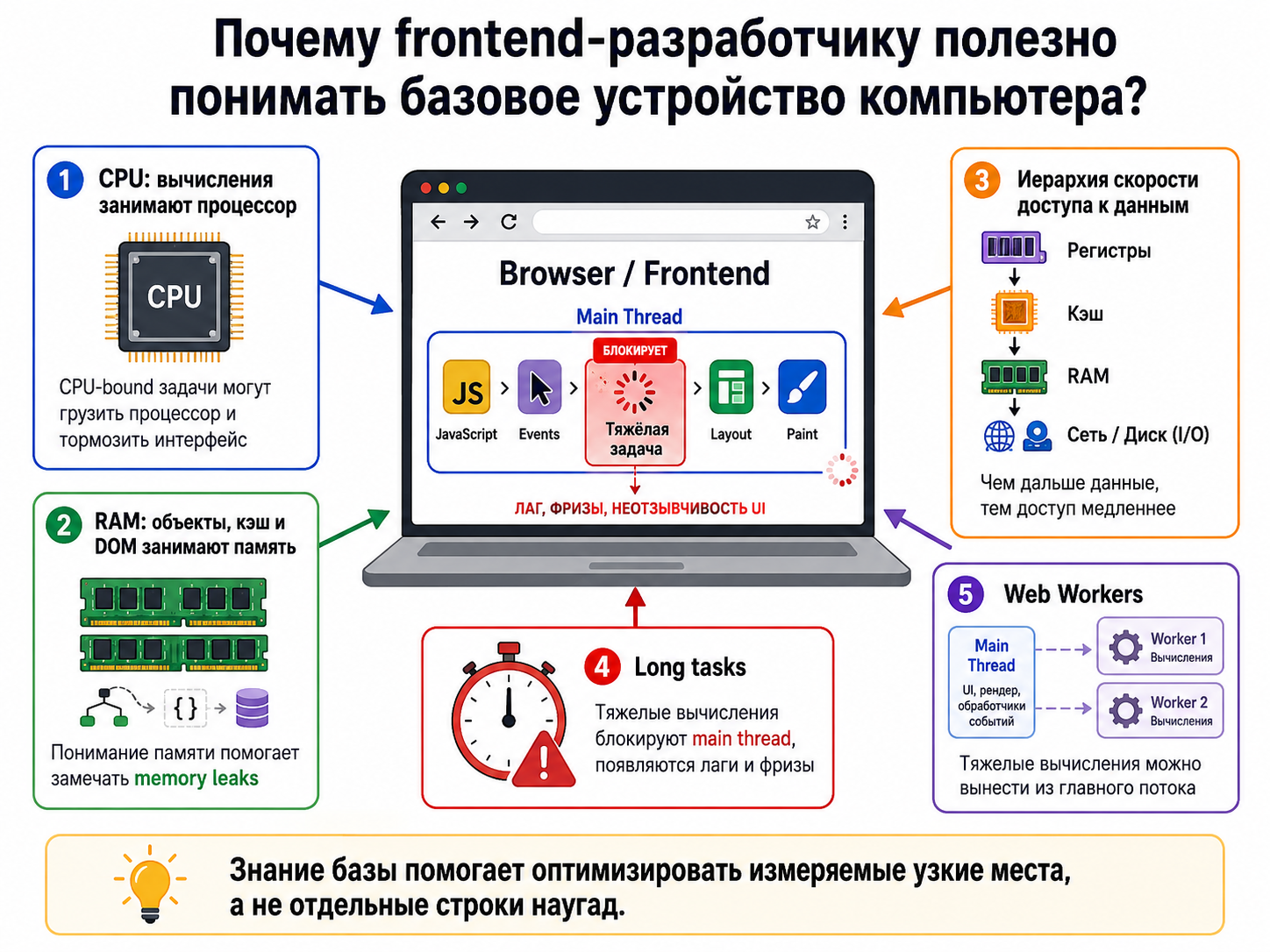
Почему frontend-разработчику полезно понимать базовое устройство компьютера?
|
Frontend-разработчику эта модель помогает понимать CPU-bound задачи, main thread (главный поток) и стоимость доступа к памяти. JavaScript выполняется не в вакууме: вычисления занимают CPU, объекты расходуют RAM, а сеть и диск (I/O) работают существенно медленнее регистров и кешей процессора. Это помогает объяснять long tasks (тяжелые задачи), лаги main thread, memory leaks (утечки памяти) и пользу Web Workers. Знание базы позволяет оптимизировать измеряемые узкие места, а не отдельные строки наугад.
|
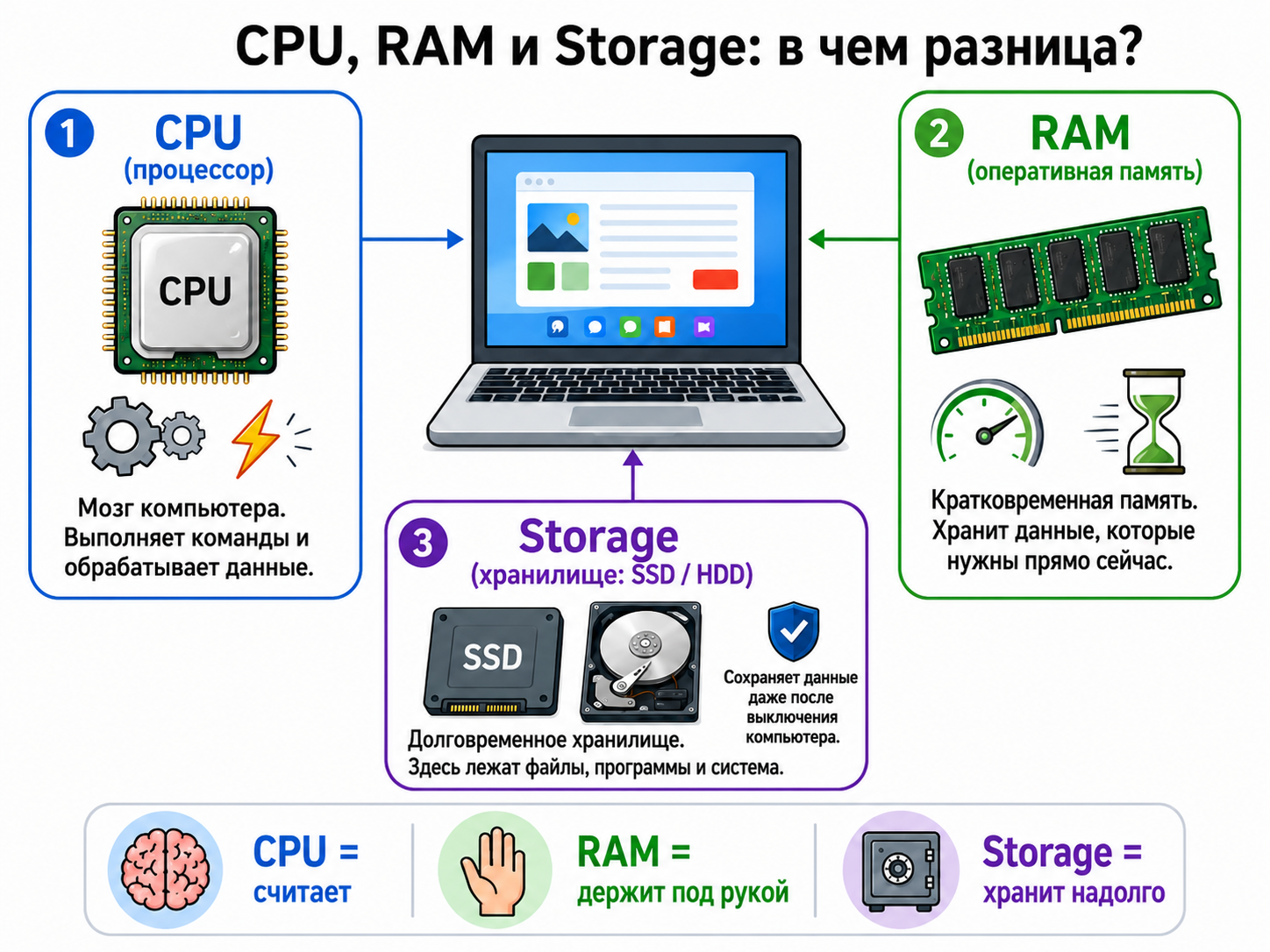
Что такое CPU, RAM и storage?
|
CPU выполняет машинные инструкции и вычисления. RAM быстро хранит данные работающих процессов, но очищается после выключения питания. Storage, например SSD, хранит файлы долговременно, но обычно имеет большую задержку доступа.
|
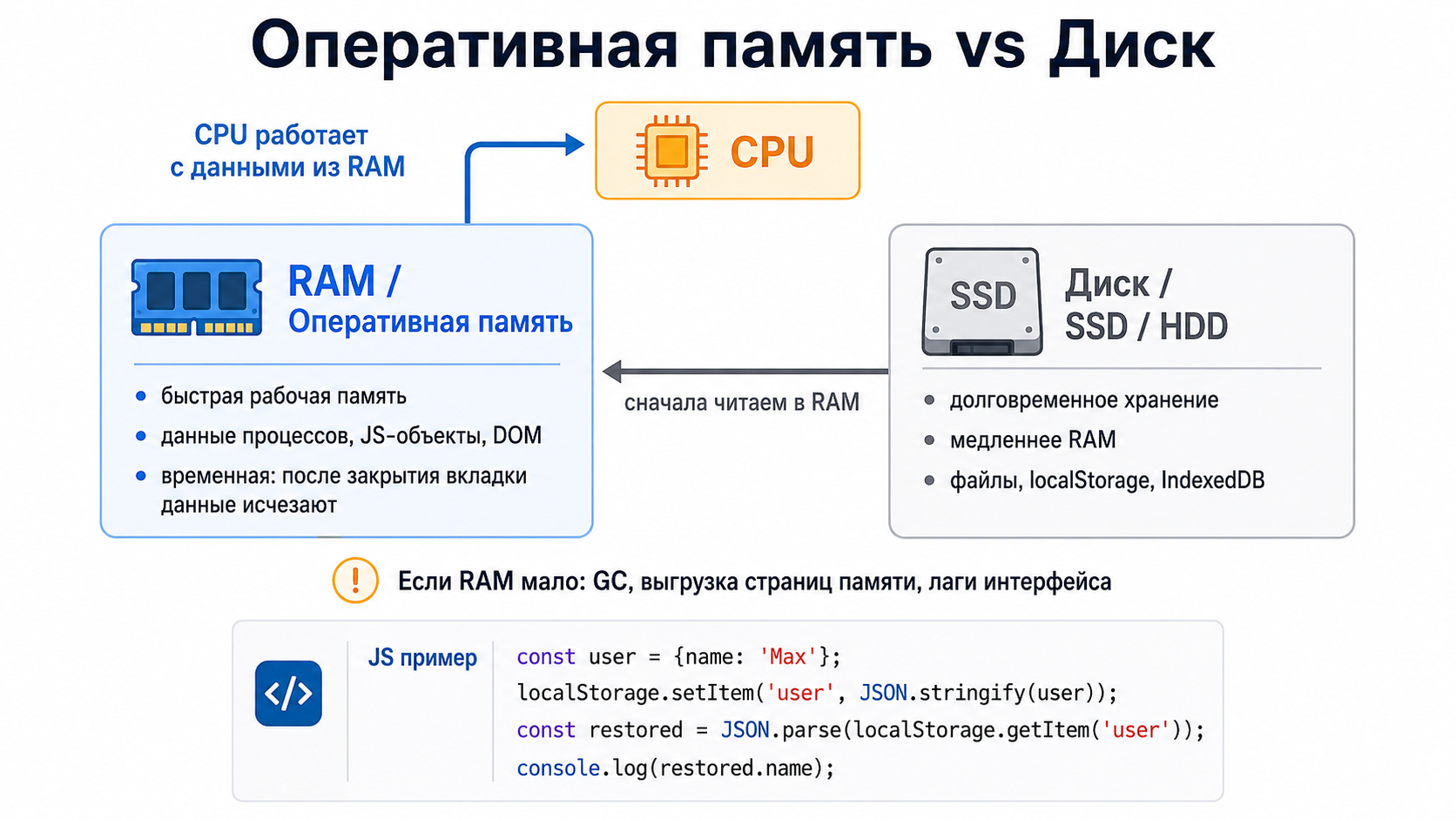
Чем оперативная память отличается от диска?
|
RAM быстрее и используется как рабочая память процессов, а диск предназначен для долговременного хранения. Данные с диска обычно сначала читаются в память, после чего CPU может с ними работать. Недостаток RAM приводит к сборке мусора, выгрузке страниц памяти и ухудшению отзывчивости.
|
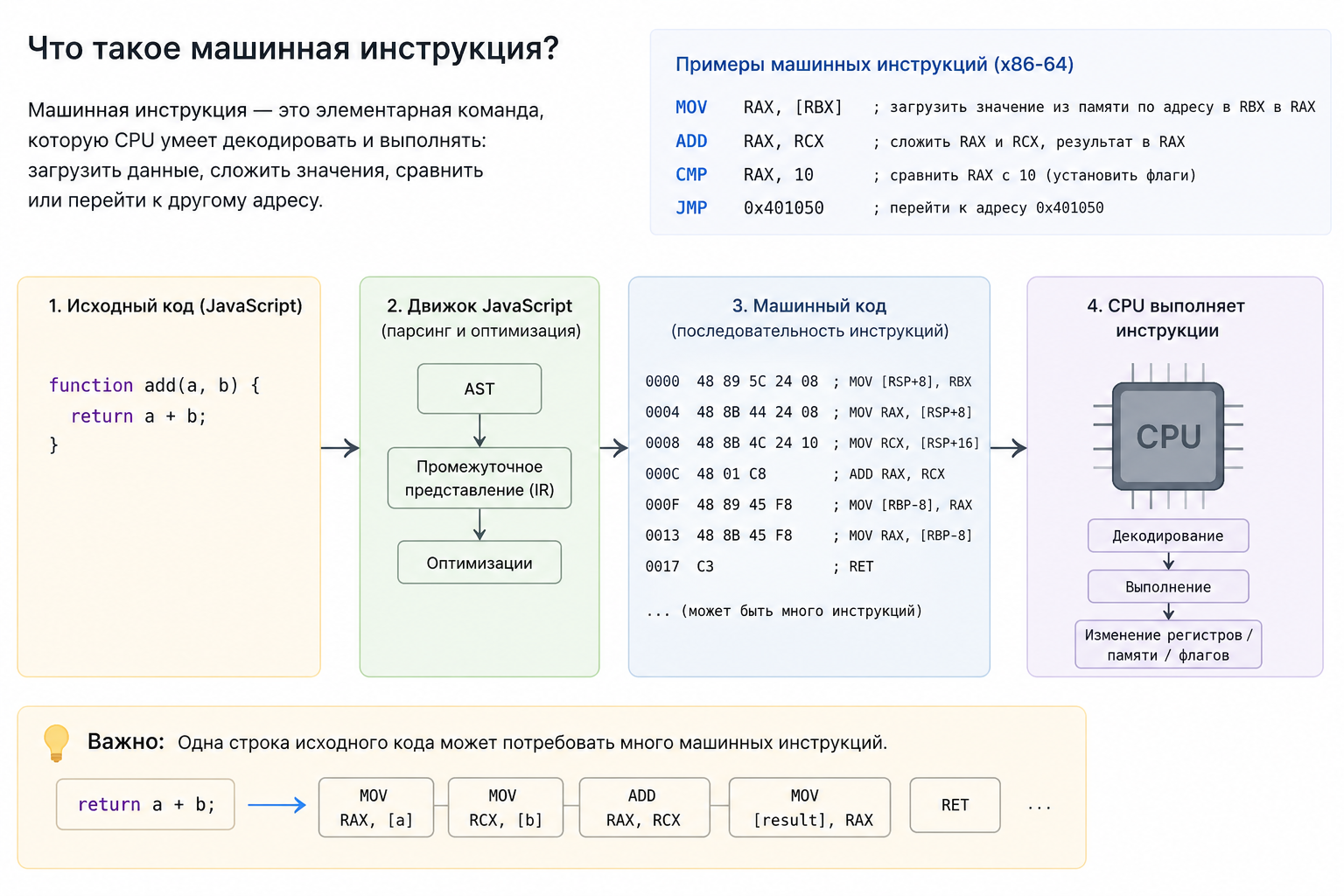
Что такое машинная инструкция?
|
Это элементарная команда, которую CPU умеет декодировать и выполнять: загрузить данные, сложить значения, сравнить или перейти к другому адресу. JavaScript сначала преобразуется движком в промежуточное представление и машинный код. Одна строка исходника может потребовать много инструкций.
|
Middle #
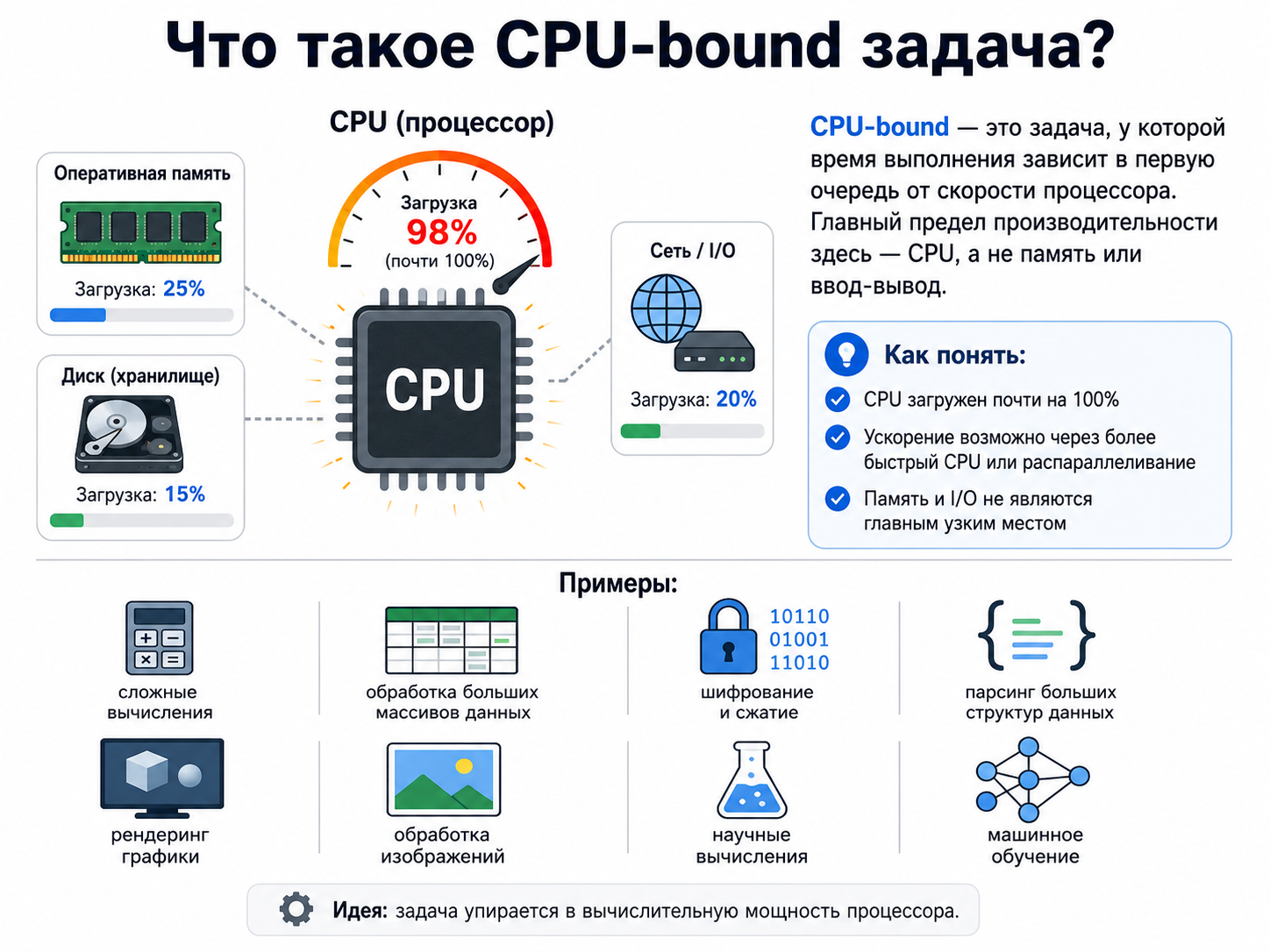
Что CPU-bound задача?
|
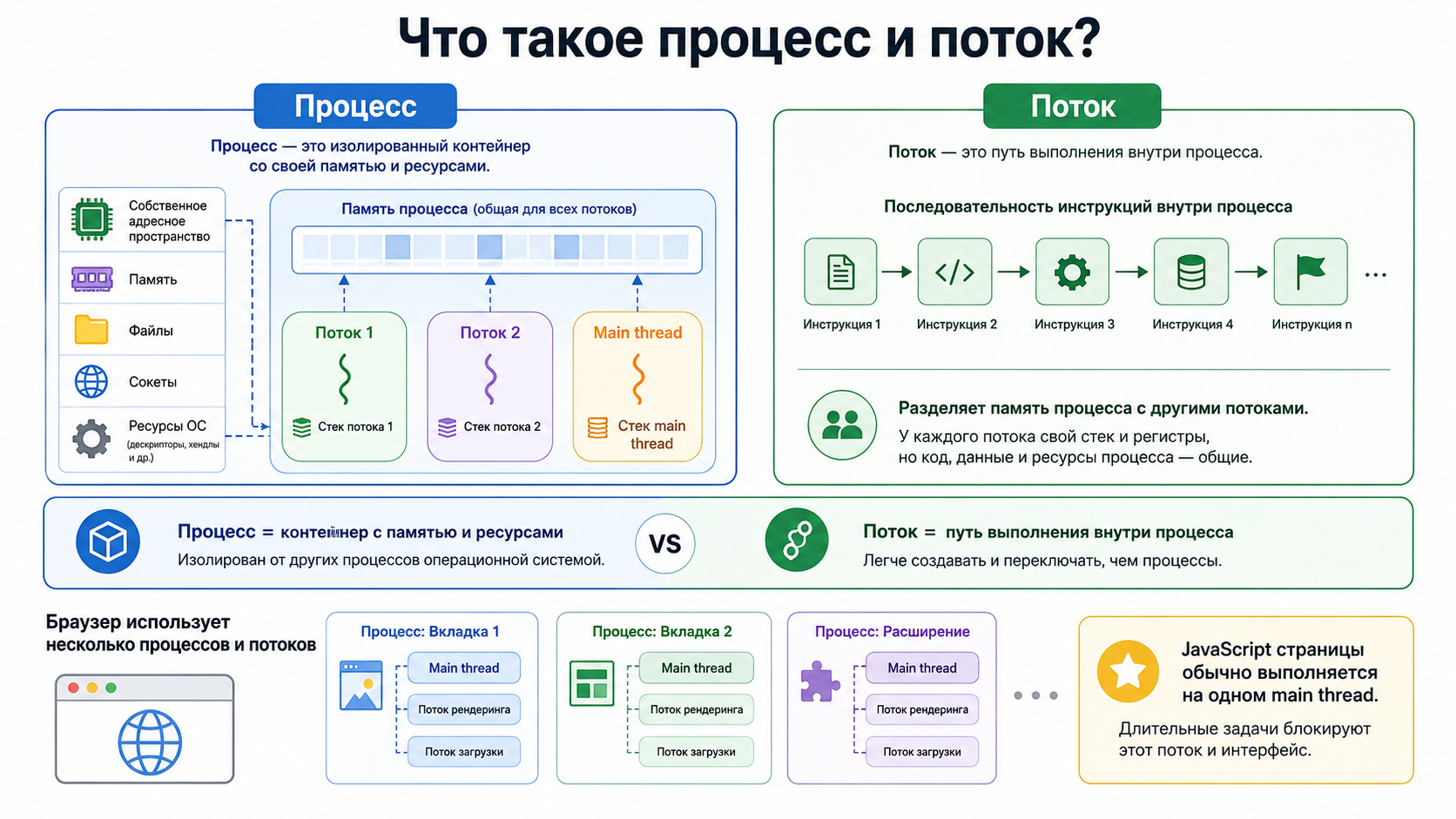
Что такое процесс и поток?
|
Процесс имеет собственное адресное пространство и ресурсы операционной системы. Поток выполняет последовательность инструкций внутри процесса и разделяет его память с другими потоками. Браузер использует несколько процессов и потоков, хотя JavaScript страницы обычно выполняется на одном main thread.
|
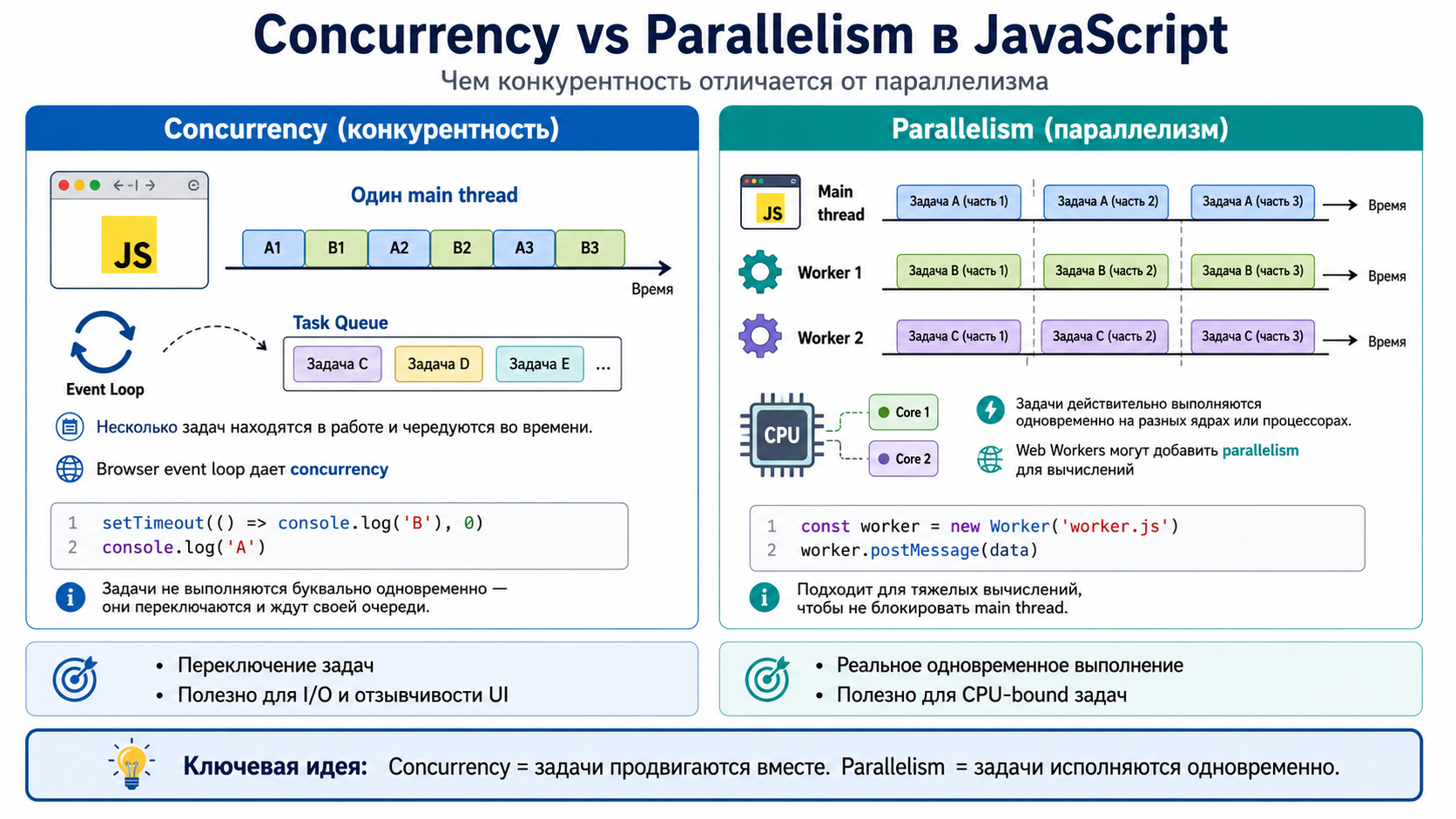
Чем concurrency (конкурентность) отличается от parallelism (параллелизм)?
|
|
Память, stack и heap #
Middle+ or Senior #
Что такое stack и heap?
|
Stack хранит frames вызовов функций и имеет строгий порядок LIFO. Heap используется для динамически создаваемых объектов с менее предсказуемым временем жизни. Конкретная реализация зависит от JavaScript engine, но эта модель полезна для понимания рекурсии и утечек.
|
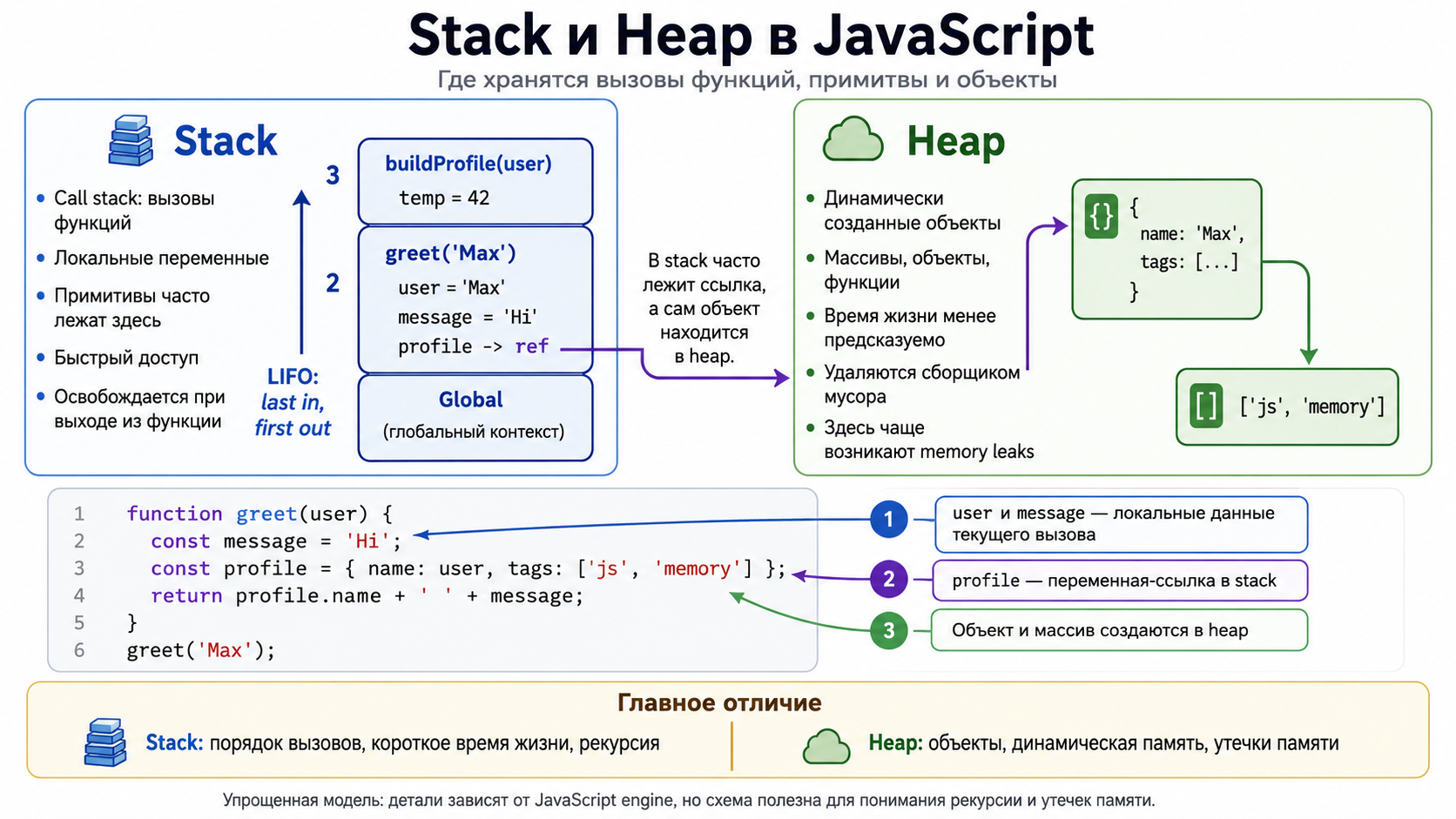
Что обычно хранится в stack?
|
В stack обычно находятся call frames: адрес возврата, локальный контекст и служебные данные вызова. Небольшие значения движок также может хранить рядом с frame, но спецификация JavaScript не закрепляет физическое размещение. Важно, что глубина stack ограничена.
|
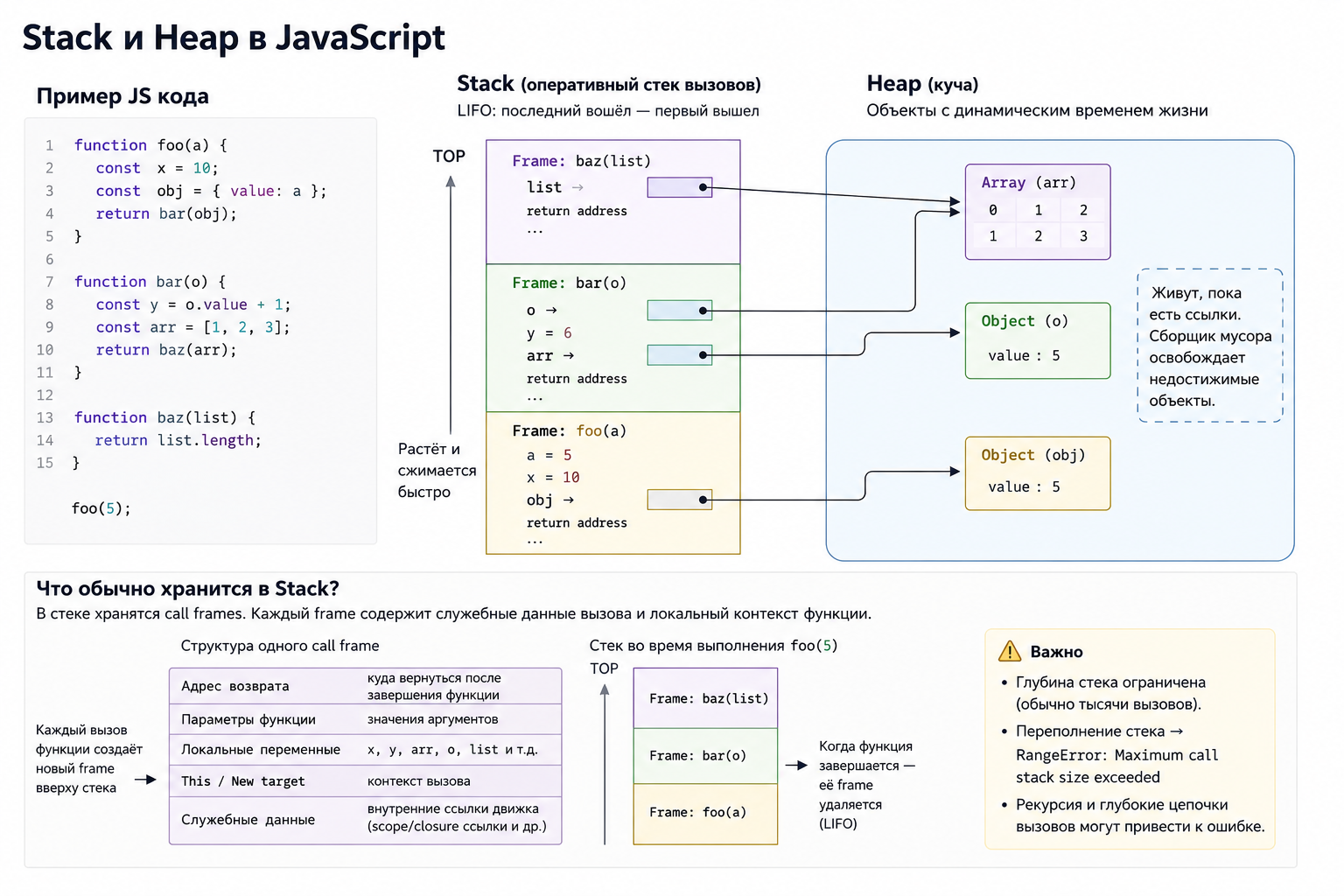
Что обычно хранится в heap?
|
В heap живут объекты, массивы, функции, замыкания и другие значения с динамическим lifetime. Сборщик мусора освобождает их, когда они становятся недостижимыми. Большое число удерживаемых объектов увеличивает memory usage и паузы GC.
|
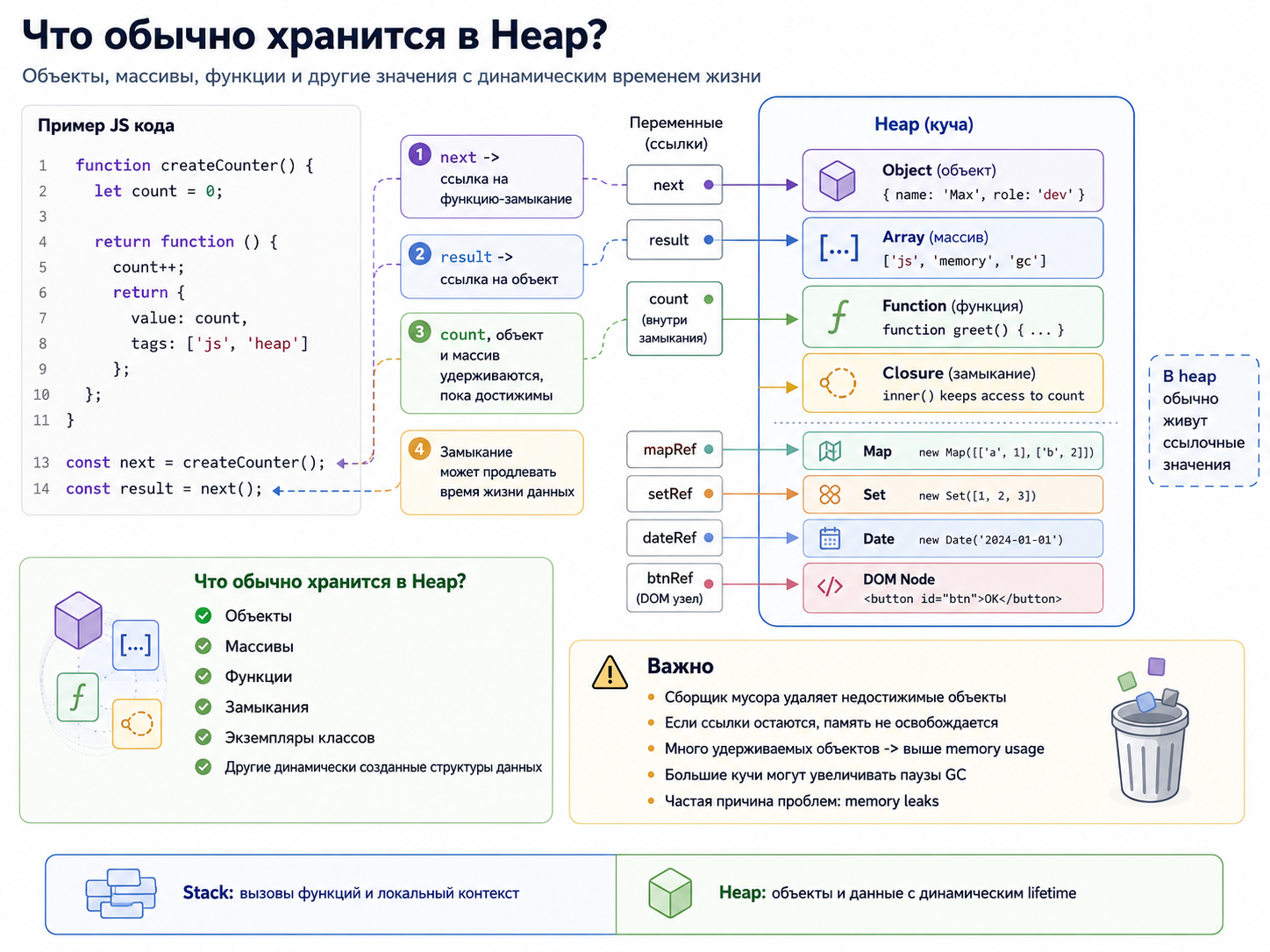
Почему объекты обычно живут в heap?
|
Размер и lifetime объекта часто неизвестны во время входа в функцию. Heap позволяет нескольким ссылкам указывать на один объект и сохранять его после завершения создавшего вызова. Stack с LIFO-порядком для такого времени жизни неудобен.
|
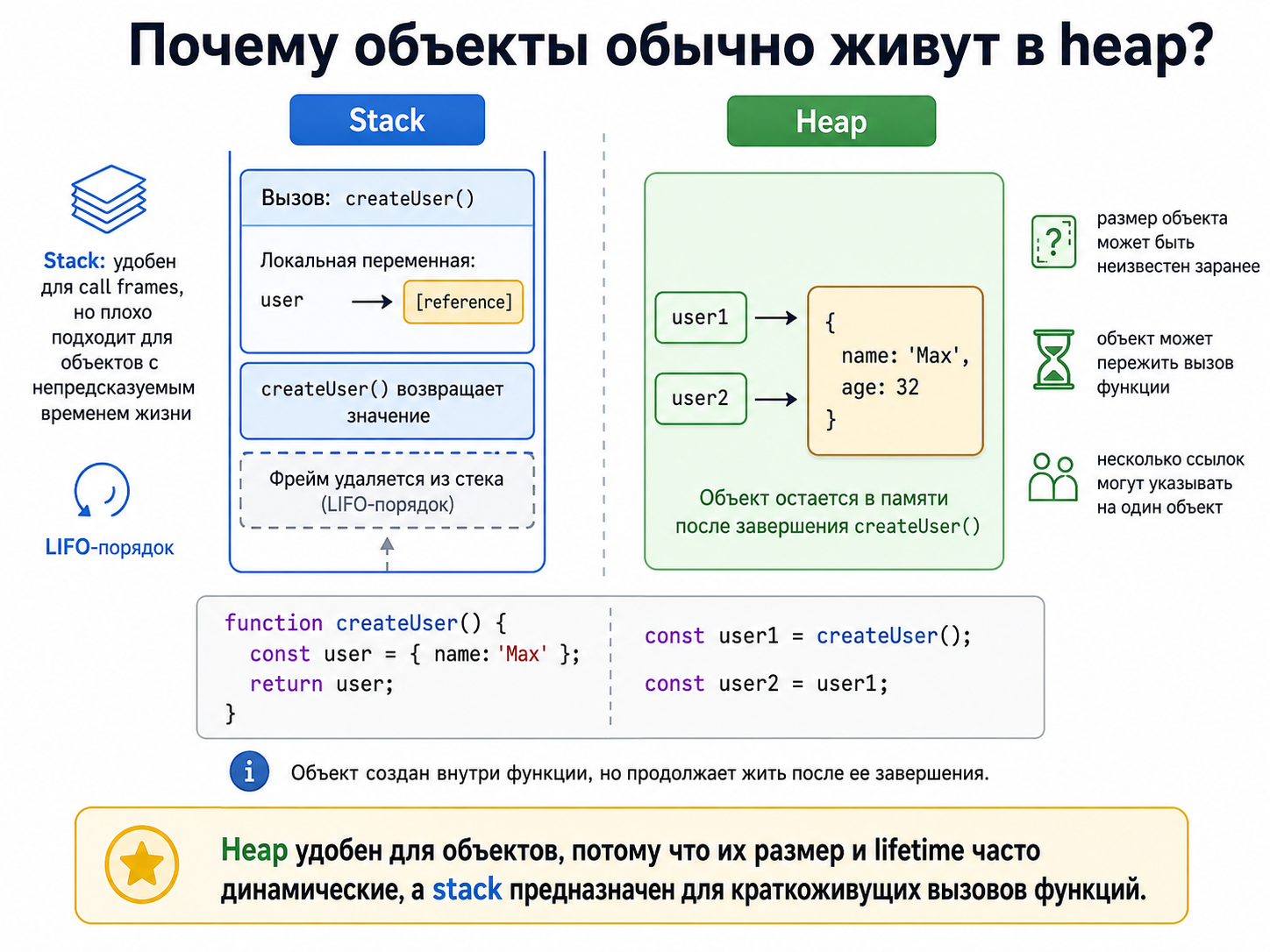
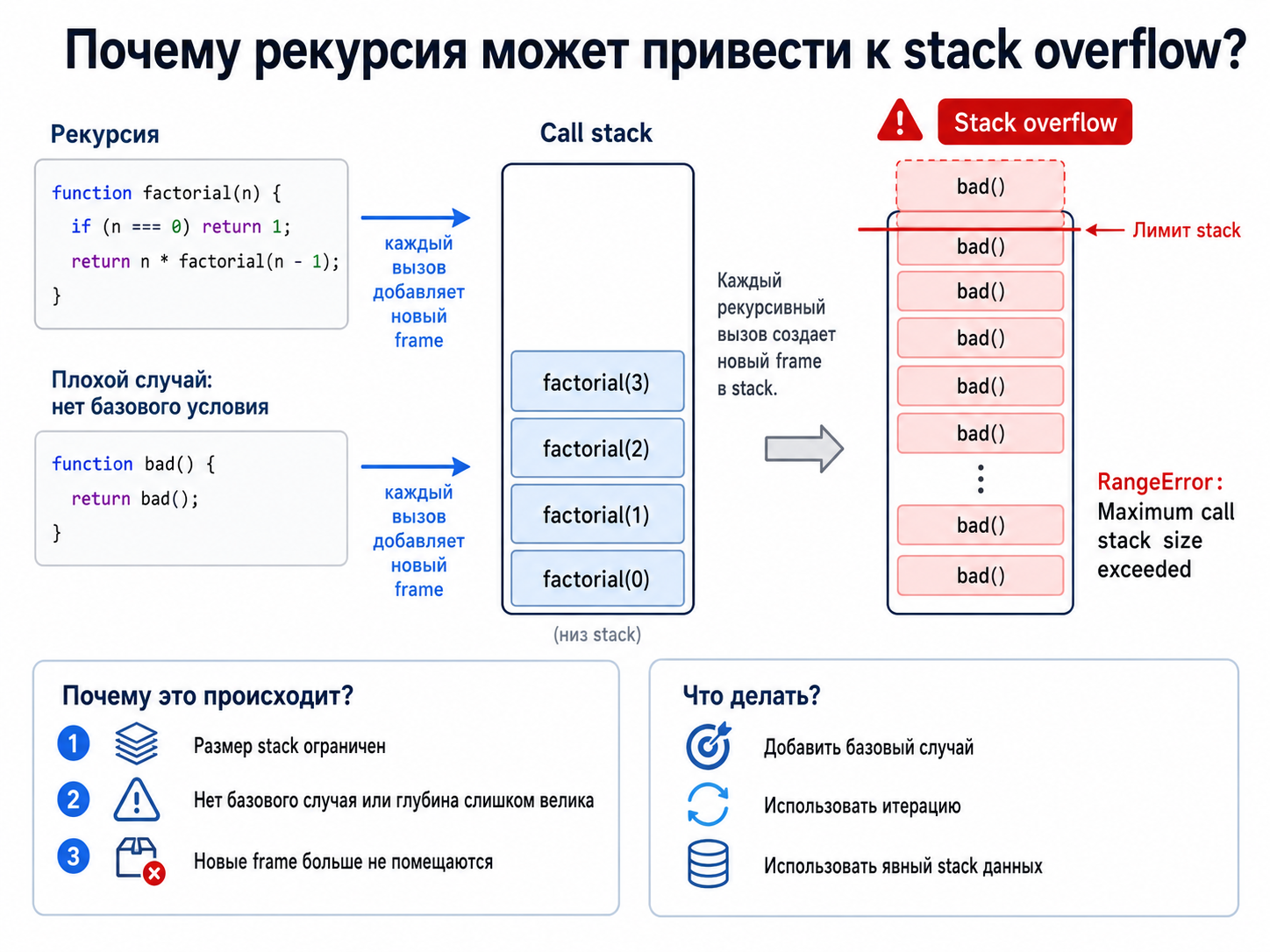
Почему рекурсия может привести к stack overflow?
|
Каждый рекурсивный вызов добавляет новый frame. Если базовый случай отсутствует или глубина слишком велика, stack
заканчивается и runtime выбрасывает
|
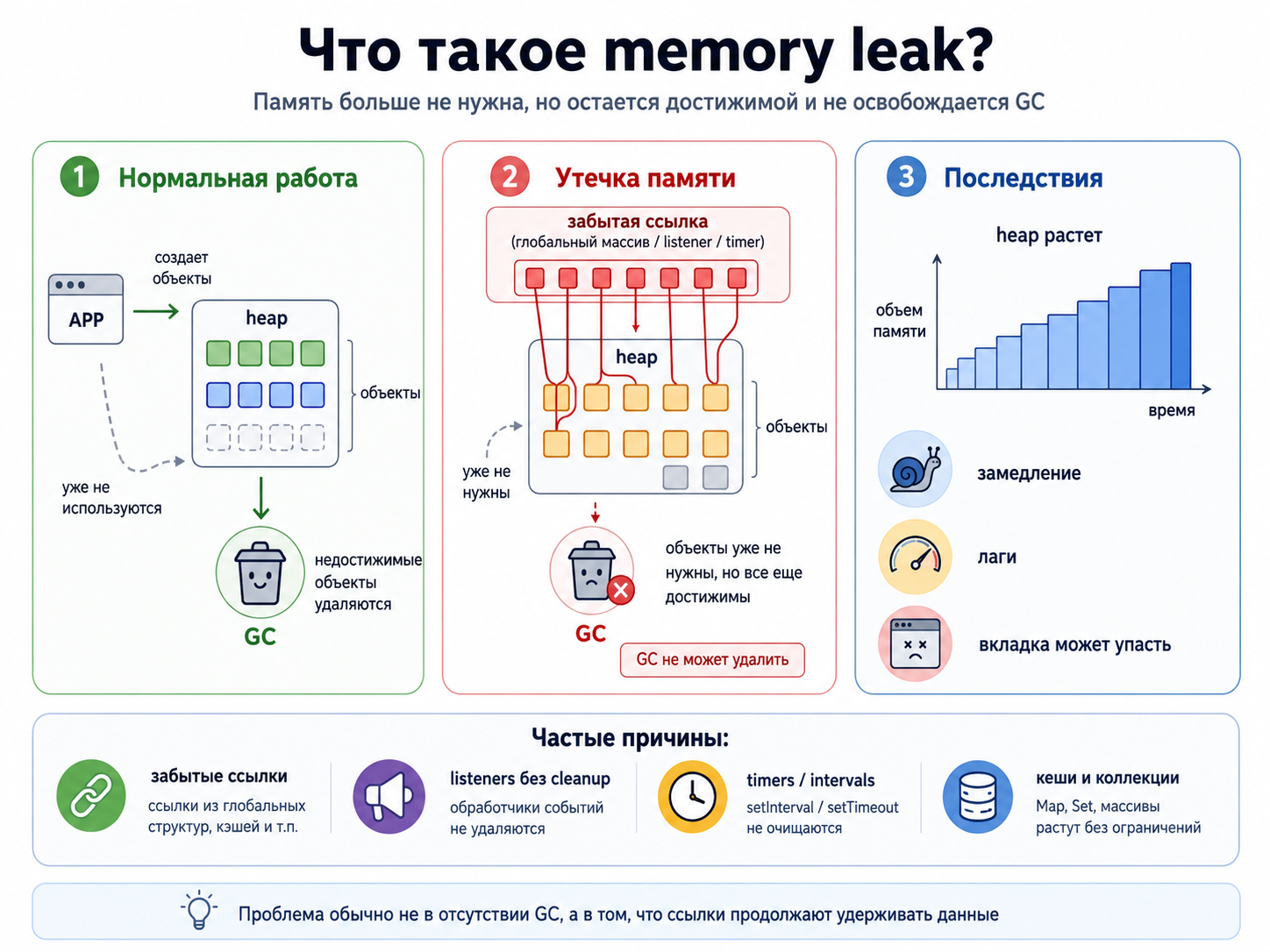
Что такое memory leak?
|
Это память, которая больше не нужна приложению, но остается достижимой и не освобождается GC. Утечка проявляется ростом heap, замедлением работы и иногда падением вкладки. Причина обычно в забытых ссылках, а не в отсутствии сборщика мусора.
|
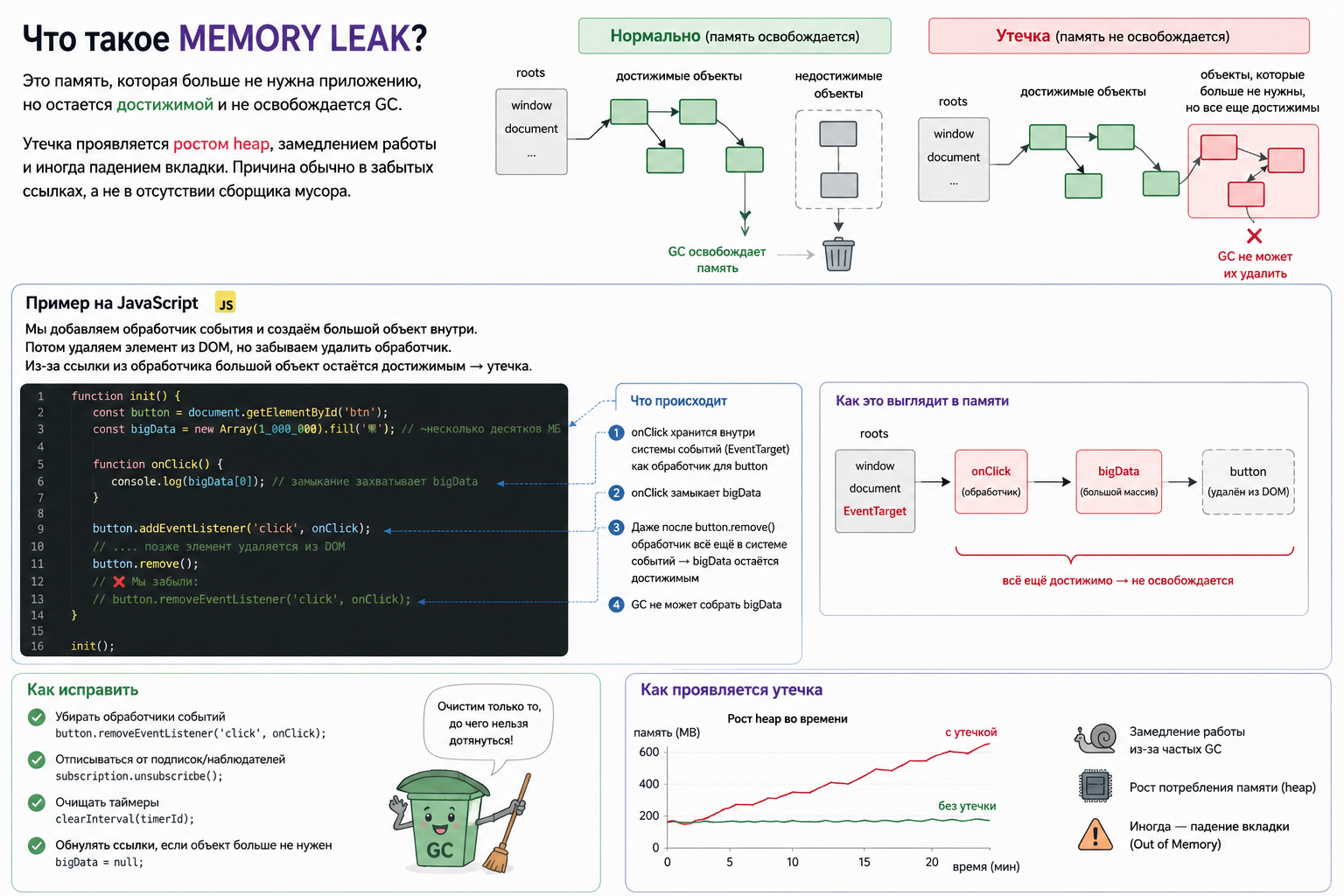
Какие memory leaks бывают во frontend?
|
Частые причины: неснятые event listeners, timers, subscriptions, глобальные коллекции, кеш без ограничения и detached DOM nodes. Замыкание может удерживать большой объект через одну ненужную ссылку. Особенно важно очищать ресурсы долгоживущих SPA-компонентов.
|
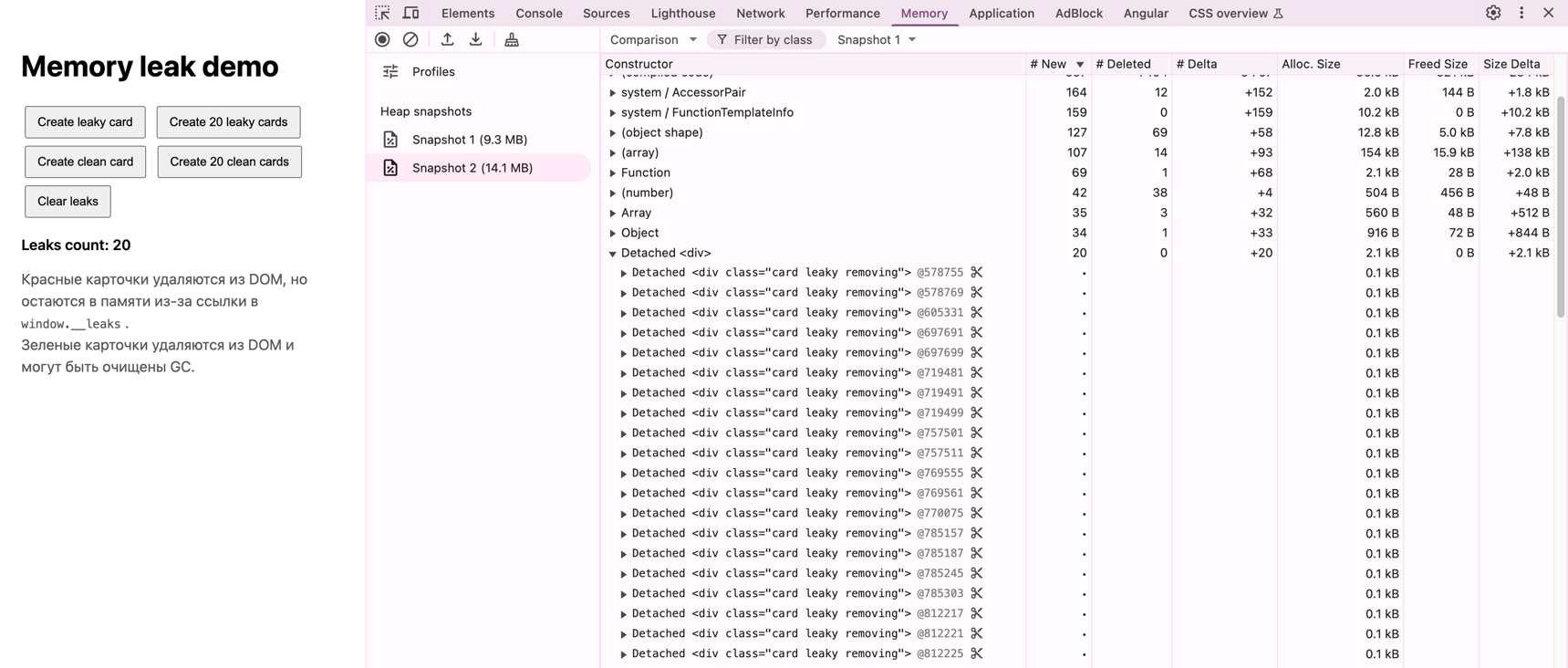
Как найти memory leak в браузере?
|
В Chrome DevTools используют Memory: Heap snapshot, Allocation instrumentation и сравнение snapshots после повторения сценария. Ищут растущее число объектов, retaining paths и detached DOM nodes. Performance Monitor помогает увидеть устойчивый рост JS heap и DOM nodes.
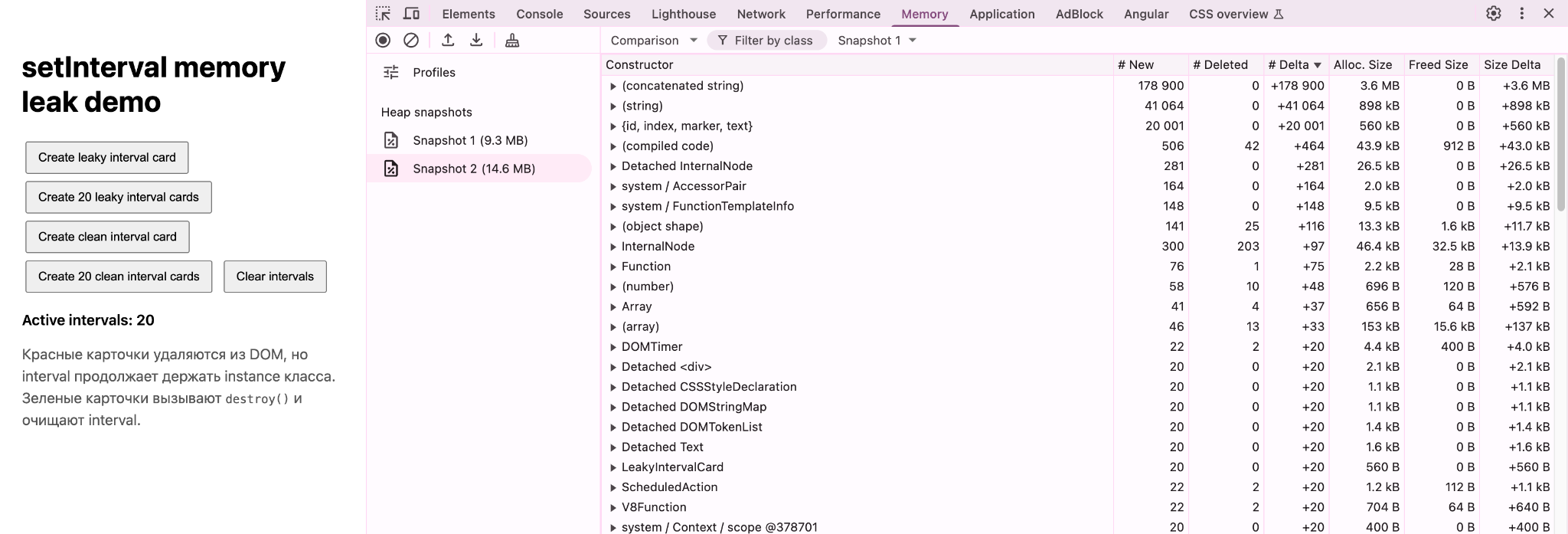
Пример с Detached Elements #Откройте пример с карточками.
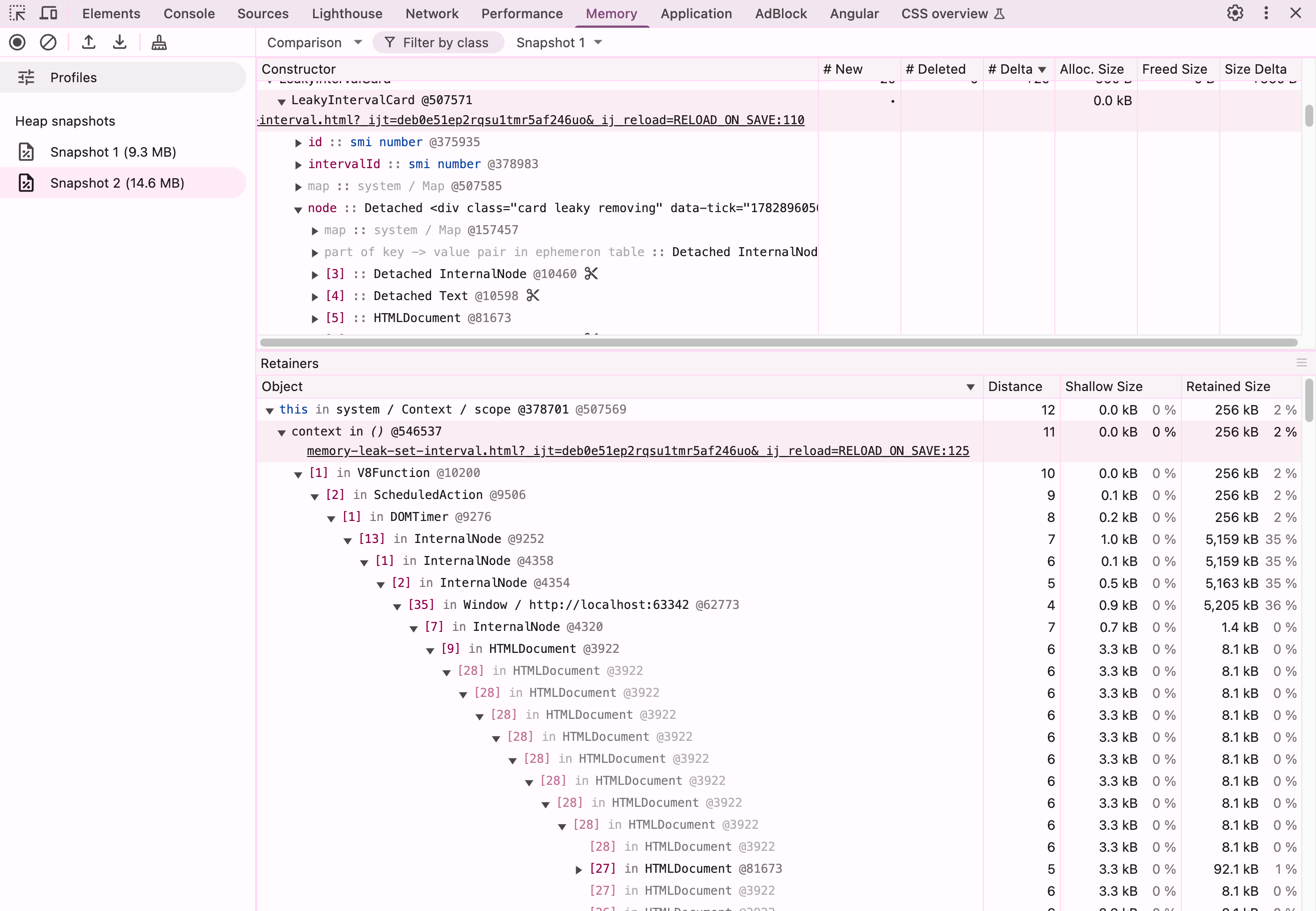
Главная мысль #Элемент исчез со страницы ≠ объект исчез из памяти. Утечка возникает не из-за setTimeout, а из-за этой строки: Именно она оставляет объект достижимым. Пример с setInterval #Откройте пример с setInterval. Проделайте аналогичные шаги примеру 1.
Главные строки:
|

GC и управление памятью #
Middle+ or Senior #
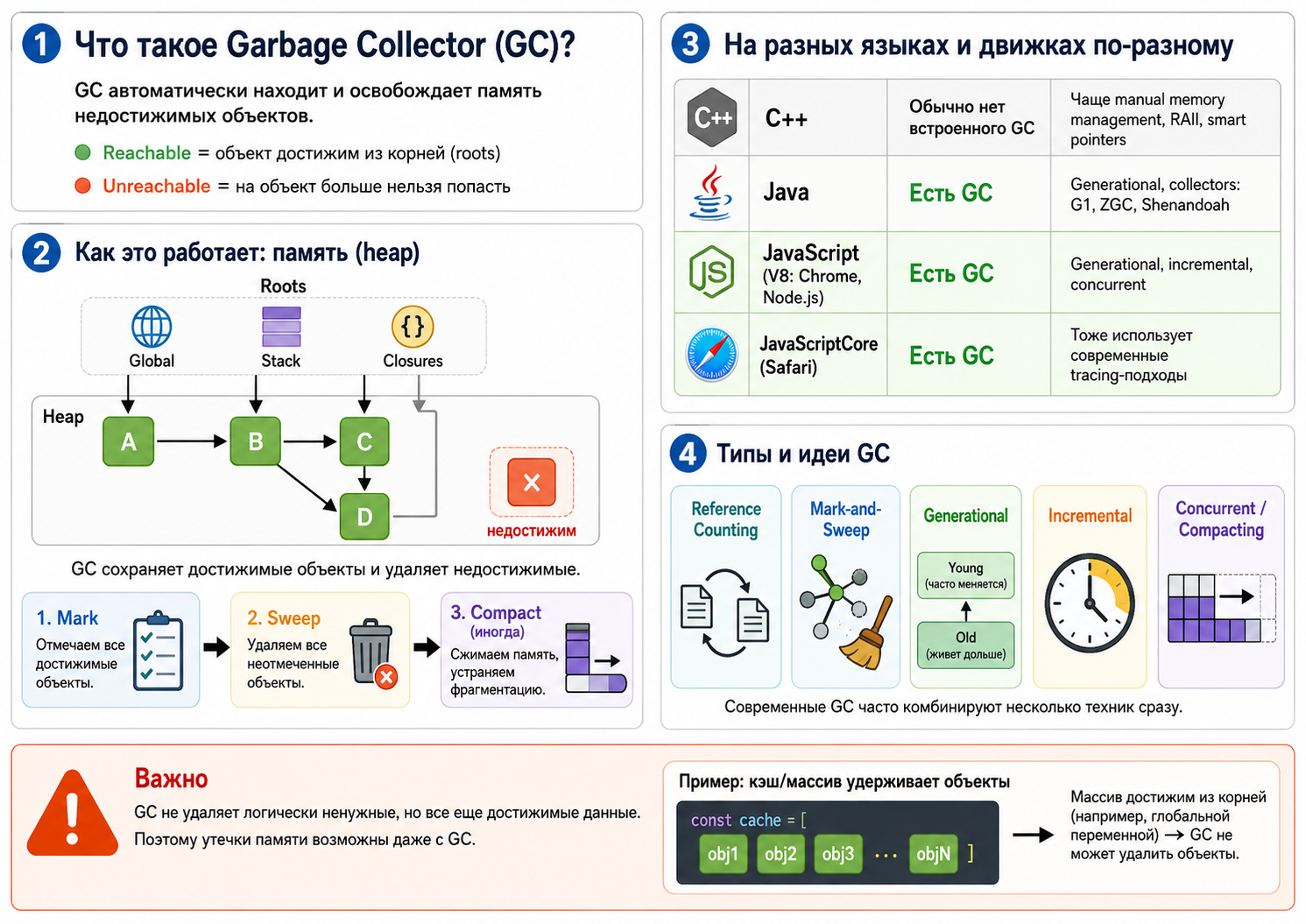
Что такое Garbage Collector?
|
GC автоматически находит и освобождает память недостижимых объектов. Современные движки используют несколько поколений и инкрементальные фазы, чтобы уменьшить длинные паузы. Автоматическая очистка не защищает от логически ненужных, но достижимых данных. |
Как GC понимает, что объект больше не нужен?
|
Движок начинает с roots: global objects, stack frames и внутренних ссылок runtime. Затем отмечает все объекты, до которых можно дойти по ссылкам. Неотмеченные объекты считаются недостижимыми и могут быть освобождены.
|
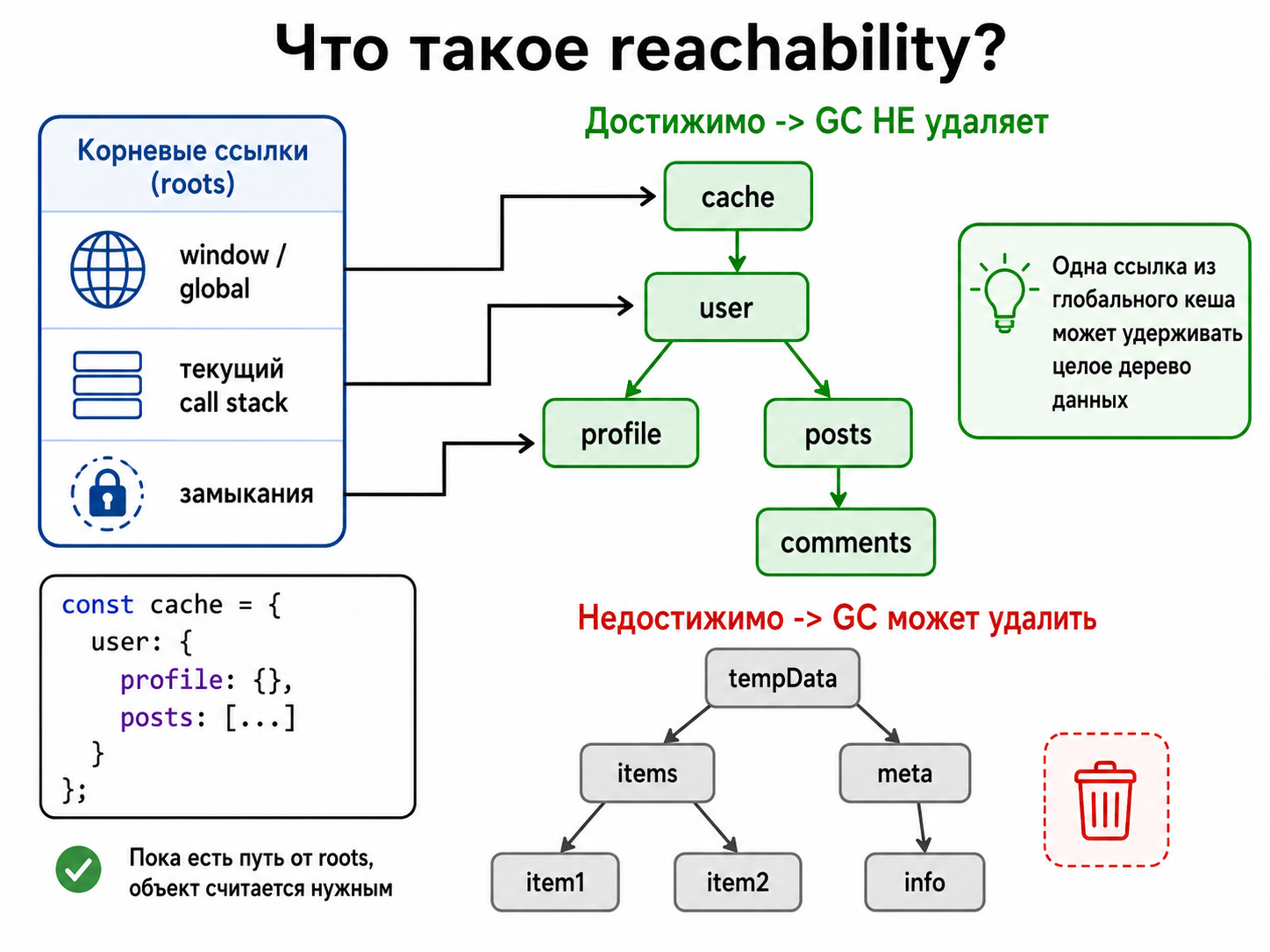
Что такое reachability?
|
Reachability — возможность добраться до значения из корневых ссылок по цепочке объектов. Пока существует такая цепочка, GC считает объект нужным. Поэтому одна ссылка из глобального кеша может удерживать большое дерево данных.
|
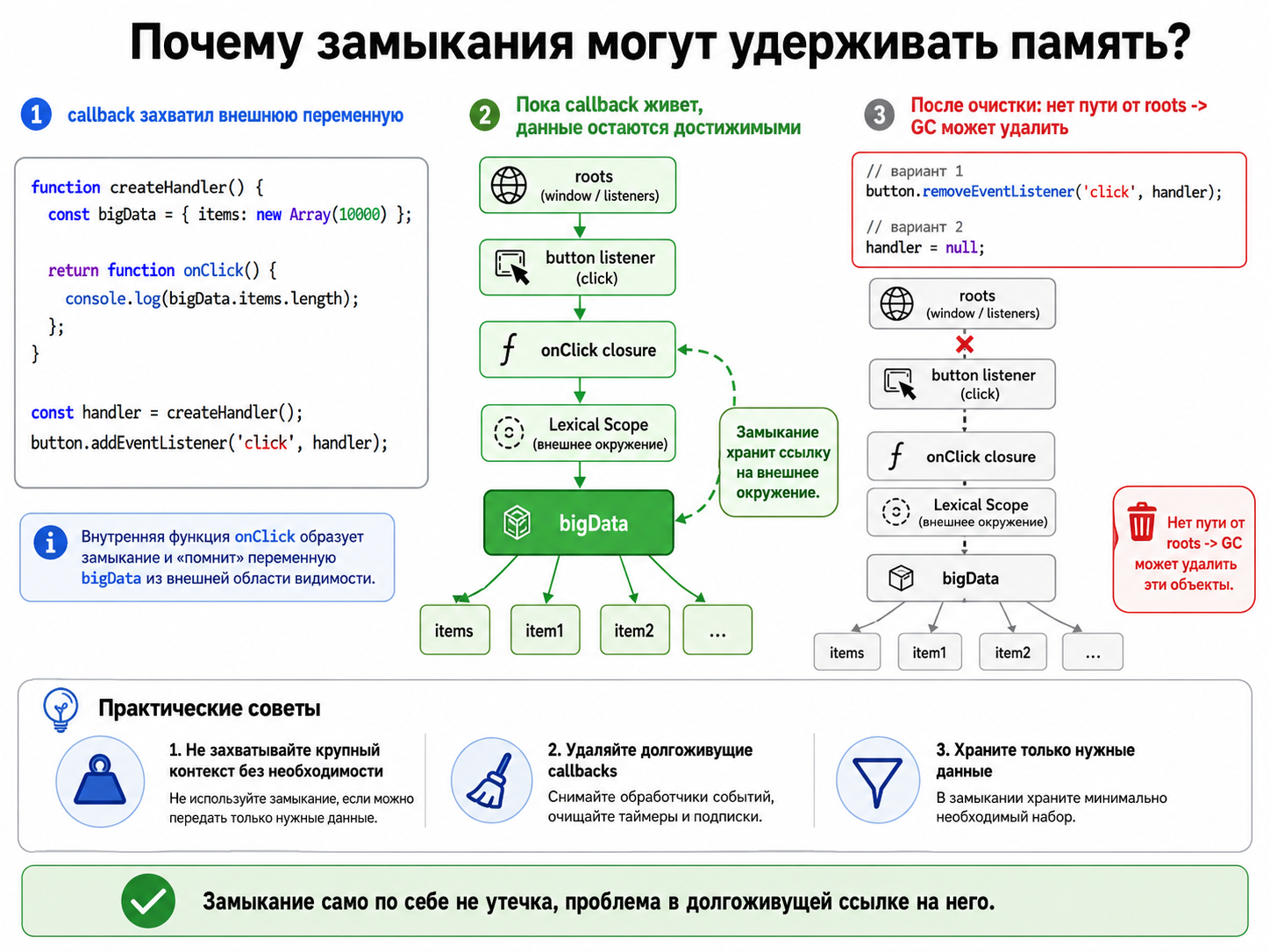
Почему замыкания могут удерживать память?
|
Функция сохраняет доступ к переменным внешней lexical scope даже после завершения внешнего вызова. Если callback живет долго, связанные данные тоже могут оставаться достижимыми. Следует не захватывать крупный контекст без необходимости и удалять долгоживущие callbacks.
|
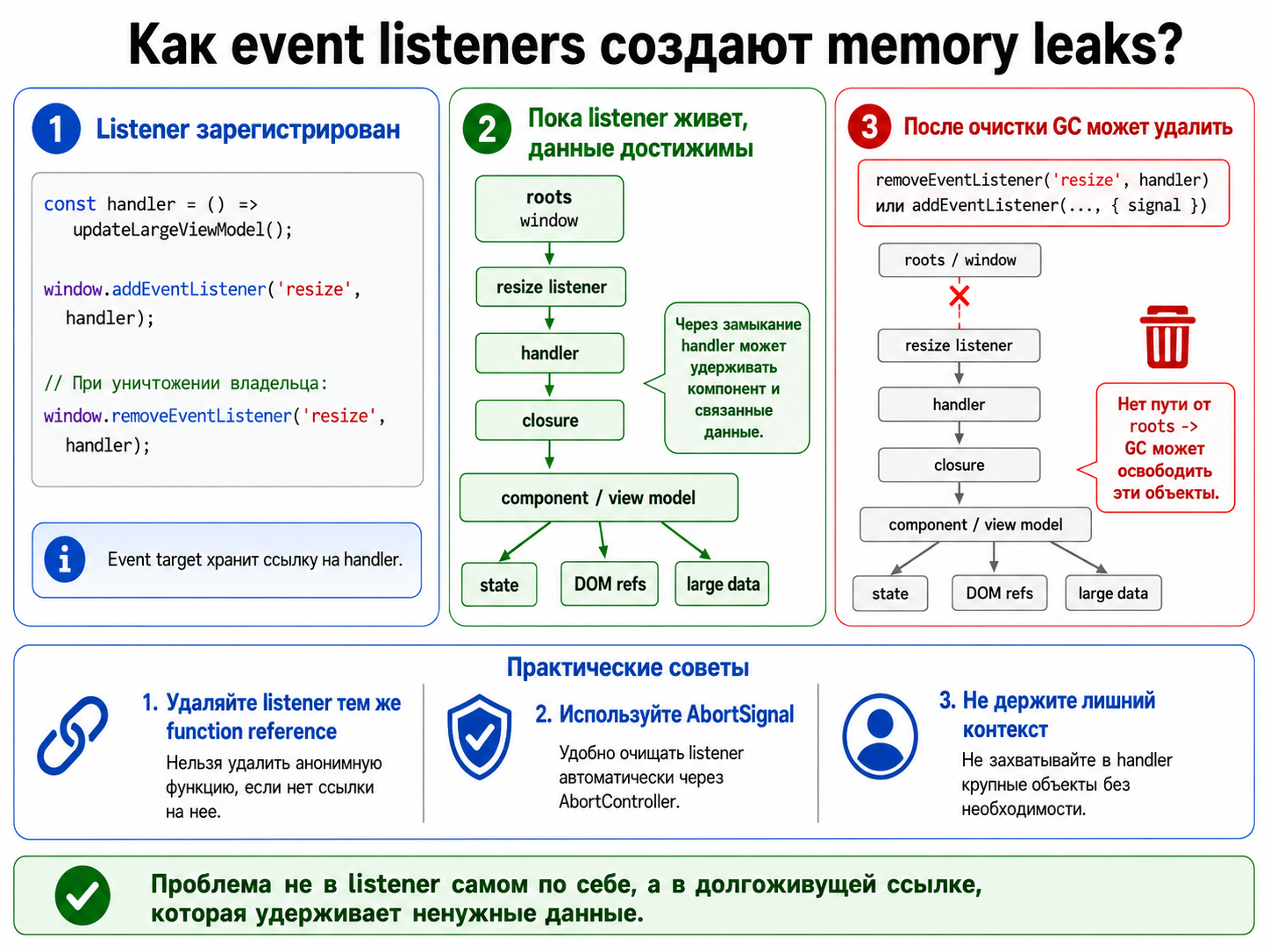
Как event listeners могут создавать memory leaks?
|
Event target хранит ссылку на handler, а handler через замыкание может удерживать компонент и данные. Listener нужно
удалять тем же function reference или регистрировать с
|
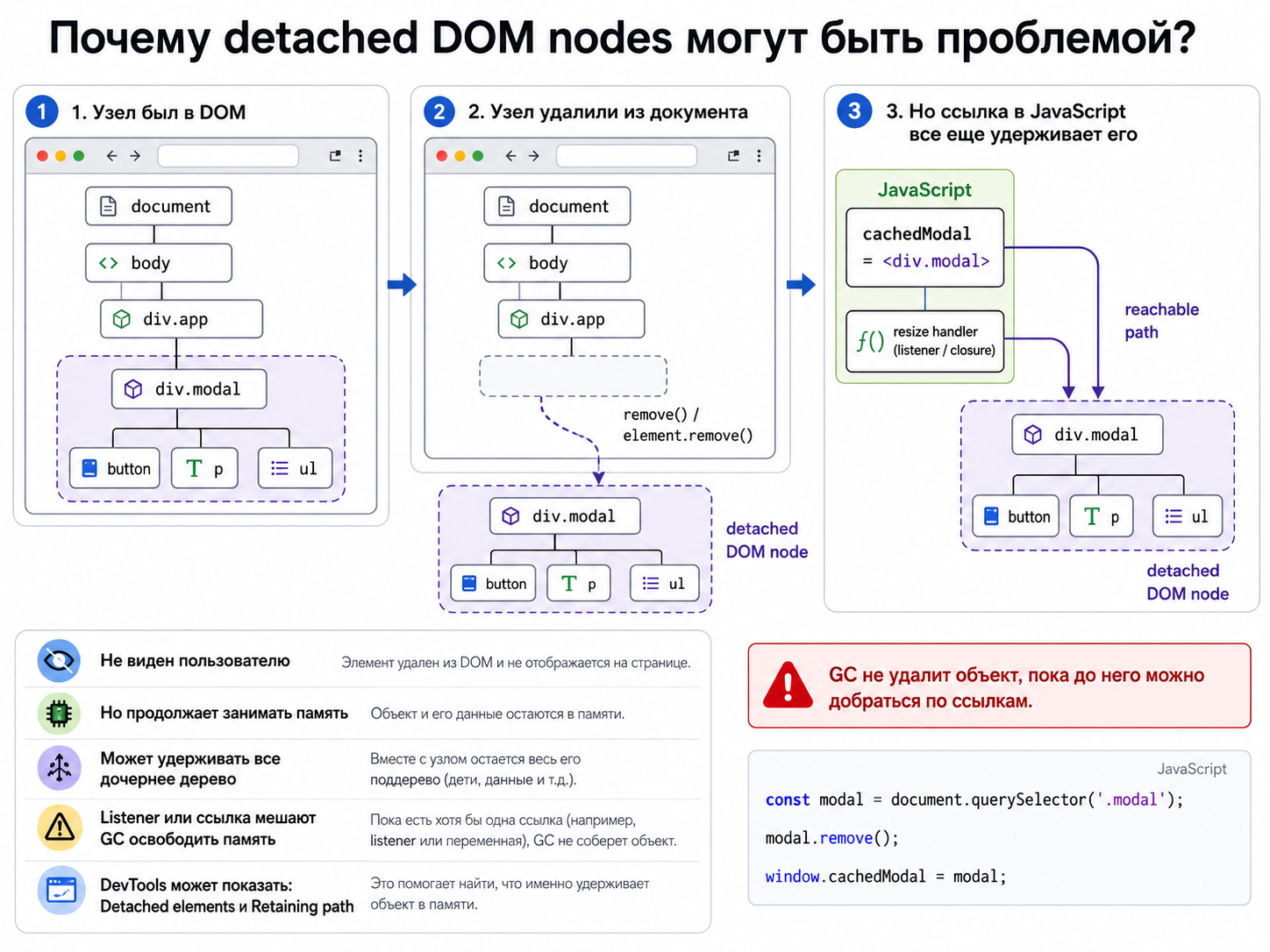
Почему detached DOM nodes могут быть проблемой?
|
Узел удален из документа, но JavaScript-ссылка или listener продолжает удерживать его и дочернее дерево. Он не виден пользователю, но занимает память. DevTools показывает такие узлы как detached elements и помогает найти retaining path.
|
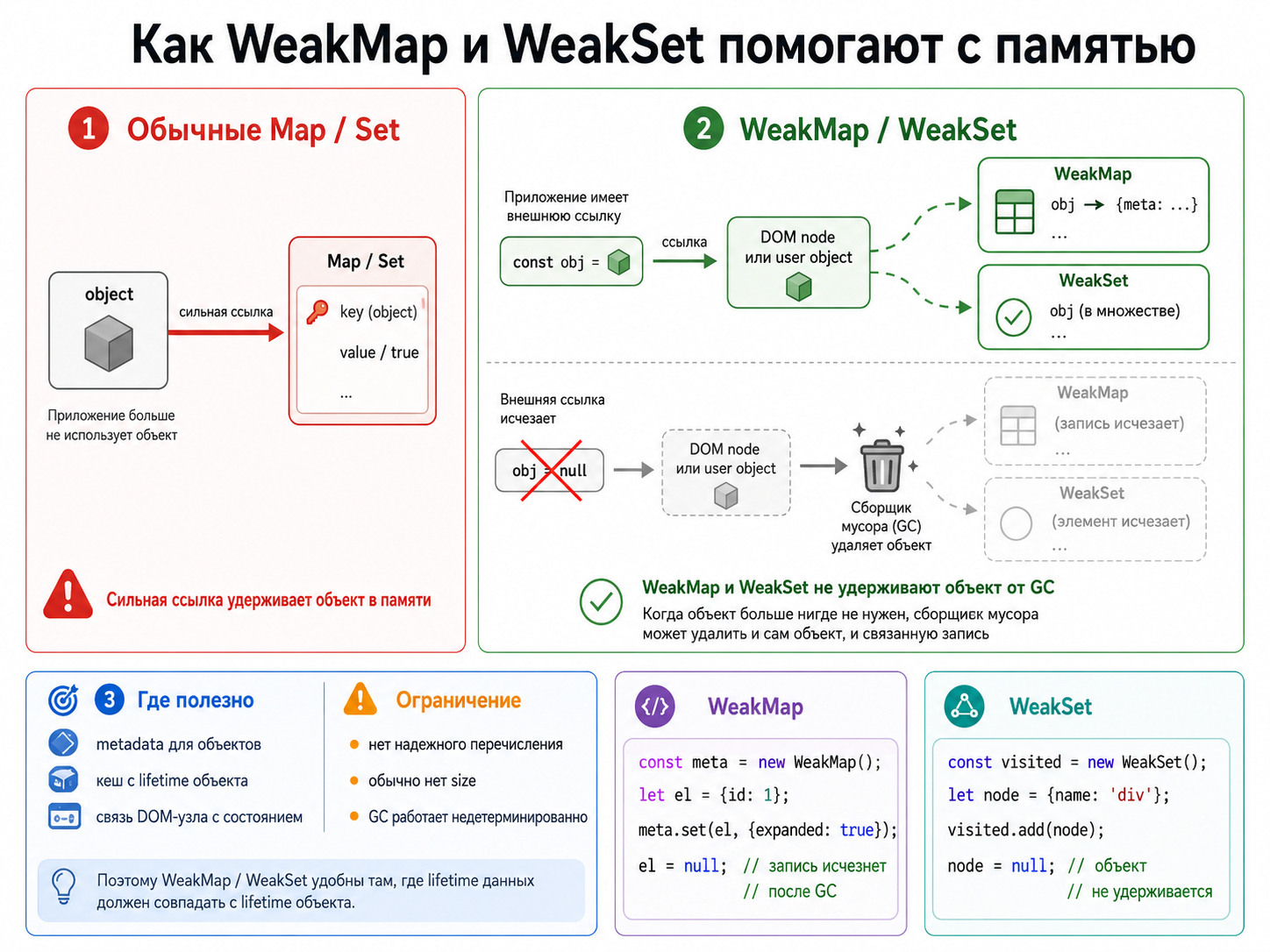
Как WeakMap и WeakSet помогают с памятью?
|
Они не удерживают объект-ключ от сборки мусора. Это удобно для metadata и кеша, lifetime которого должен совпадать с lifetime объекта. Их содержимое нельзя надежно перечислять, потому что GC работает недетерминированно.
|
Можно ли вручную вызвать GC в JavaScript?
|
В обычном web-коде нет стандартного API для принудительного GC. Движок сам выбирает момент сборки на основе давления на память и внутренних эвристик. Правильное решение — удалить ненужные ссылки и ресурсы, а не пытаться управлять GC. |
Алгоритмы и структуры данных для frontend #
Junior #
Что такое дерево и где деревья встречаются в Angular-приложении?
|
Дерево — иерархическая структура из узлов, где у узла может быть родитель и дочерние узлы. Во frontend деревья встречаются постоянно: DOM tree, accessibility tree, component tree, Angular Router tree, DI tree, Reactive Forms tree, AST в TypeScript/ESLint/Babel. Обход дерева нужен для поиска узла, валидации вложенной формы, построения меню, анализа AST или сериализации состояния. DFS удобно идет вглубь ветки, BFS обходит уровень за уровнем. |
Что такое граф и где графы встречаются во frontend-разработке?
|
Граф состоит из вершин и связей между ними. Directed graph имеет направленные ребра, undirected graph — связи без направления. Граф может храниться как adjacency list или adjacency matrix. Во frontend графы встречаются в routing flows, state machines, dependency graph bundler-а, Nx affected graph, module federation dependencies, диаграммах, permission models и формах с зависимыми полями. Cycle в dependency graph часто означает архитектурную проблему: модули начинают зависеть друг от друга, сборка и тесты становятся хрупкими. DFS помогает находить cycle, BFS — искать кратчайший путь по числу переходов в простом графе. |
Что такое NP-complete и нужно ли это frontend-разработчику?
|
NP-complete — класс задач, для которых неизвестен быстрый алгоритм общего вида, а перебор вариантов быстро становится непрактичным. Для frontend это редко повседневная тема, но идея полезна при обсуждении scheduling, layout, оптимизации маршрутов, упаковки элементов и сложных combinatorial constraints. На интервью достаточно объяснить практический вывод: если точное решение слишком дорогое, выбирают ограничения, эвристики, приближенный алгоритм, предварительный расчет на сервере или упрощение продукта. |
Middle #
Почему Array.includes внутри filter может случайно дать O(n²)?
|
Если Так поиск по выбранным id становится в среднем |
Как выбрать между Array, Object, Map и Set?
Для UI-состояния структура должна выражать сценарий. Если список нужен для отображения, часто оставляют |
Что значит stable sort и почему это важно для UI?
|
Stable sort сохраняет относительный порядок элементов, которые считаются равными comparator-ом. Это важно для таблиц: если пользователь сначала отсортировал список по имени, а потом по роли, элементы с одинаковой ролью могут сохранить предыдущий порядок по имени. Современный JavaScript требует стабильную сортировку |
Чем отличаются preorder, inorder, postorder, DFS и BFS?
|
DFS идет в глубину. Preorder обрабатывает узел до детей, postorder — после детей, inorder применим прежде всего к бинарным деревьям и обходит левую ветку, узел, правую ветку. BFS идет по уровням и обычно использует очередь. Он удобен, когда нужно найти ближайший подходящий узел или обработать иерархию слоями. В Angular-практике preorder похож на обработку route/config tree сверху вниз, postorder удобен для агрегации валидности детей формы, а BFS может пригодиться для поиска ближайшего видимого пункта в древовидном UI. |
Что такое BST и почему он не всегда дает O(log n)?
|
Binary Search Tree хранит меньшие значения в левом поддереве, большие — в правом. Если дерево сбалансировано, поиск,
вставка и удаление работают за Если добавлять уже отсортированные значения в обычный BST без балансировки, дерево может выродиться в цепочку, и поиск
станет Frontend-разработчику редко нужно писать BST руками. Важнее понимать идею упорядоченной структуры и почему обычный
массив с бинарным поиском, |
Чем adjacency list отличается от adjacency matrix?
|
Adjacency list хранит для каждой вершины список соседей. Он обычно экономнее для sparse graph, где связей мало относительно числа возможных связей. Adjacency matrix хранит таблицу Для большинства frontend-задач adjacency list через |
Когда рекурсию лучше заменить итерацией во frontend-коде?
|
Рекурсия хорошо выражает дерево или вложенную структуру, но глубина call stack ограничена. Если данные могут прийти от
API и быть очень глубокими, рекурсивный обход рискует упасть с Итерация с явным stack или queue безопаснее для больших структур и позволяет проще разбивать работу на chunks, чтобы не блокировать main thread. |
Что такое bitwise operations и почему в JavaScript с ними нужно быть осторожным?
|
Bitwise operations работают с битовым представлением числа: Битовые маски могут пригодиться для компактного набора flags, permissions или низкоуровневой работы с binary data. Но в
обычном frontend-бизнес-коде читаемый объект, |
Middle+ or Senior #
Зачем frontend-разработчику понимать Big O?
|
Big O помогает оценить, как растет стоимость операции при увеличении входных данных. Для frontend это не абстрактная математика: фильтрация таблицы, группировка списка, сортировка на клиенте, поиск выбранных элементов и построение дерева меню могут выполняться на main thread и напрямую влиять на отзывчивость UI. Важно помнить, что Big O не заменяет профилирование. |
Как оценить сложность фильтрации, сортировки и группировки списка на клиенте?
|
Фильтрация одним проходом обычно стоит Для Angular важно не только вычисление, но и rendering. Даже быстрый алгоритм может привести к лагам, если после него отрисовать тысячи DOM-узлов без virtual scroll, pagination или server-side filtering. |
Где во frontend встречаются stack, queue и priority queue?
|
Stack работает по LIFO. Во frontend он встречается как call stack, undo/redo history, breadcrumbs навигации назад, обход дерева DFS без рекурсии. Queue работает по FIFO. Примеры: очередь toast-уведомлений, upload tasks, последовательные save operations через
Priority queue отдает элемент с наибольшим или наименьшим приоритетом. В UI она нужна редко, но может пригодиться для планирования фоновых задач, обработки событий по важности или алгоритмов графов. В обычном бизнес-коде часто лучше начать с читаемого массива и сортировки, если объем маленький и профиль не показывает проблему. |
Что такое binary search и где он может пригодиться во frontend?
|
Binary search ищет значение в отсортированном массиве, каждый шаг отбрасывая половину диапазона. Сложность поиска —
Во frontend бинарный поиск редко нужен для обычных UI-списков. Он полезнее в больших данных: поиск позиции в timeline, виртуальный скролл с переменной высотой строк, графики, диапазоны дат, nearest point на canvas. |
Чем quicksort, mergesort и heapsort отличаются на уровне идеи?
|
Quicksort выбирает pivot и делит данные на элементы меньше и больше pivot. В среднем он быстрый, но плохой выбор pivot
может привести к Mergesort делит массив пополам, сортирует части и сливает их. Он стабильно дает Heapsort строит heap и последовательно извлекает минимум или максимум. Он работает за В прикладном JS/TS-коде обычно используют встроенный |
Что такое heap и как он связан с priority queue?
|
Heap — деревообразная структура, где родитель имеет приоритет не ниже или не выше детей. Binary heap обычно хранится в
массиве: для индекса Priority queue часто реализуют через heap: вставка и извлечение приоритетного элемента стоят Во frontend это может пригодиться для планировщика фоновых задач, графовых алгоритмов или обработки большого потока событий по приоритетам. Для обычного UI-состояния heap обычно избыточен. |
Что такое memoization и чем она отличается от caching?
|
Memoization — частный случай кеширования результата чистой функции по ее аргументам. Если вход тот же, можно вернуть сохраненный результат без повторного вычисления. Caching шире: можно кешировать HTTP-ответы, изображения, compiled templates, computed state или expensive selectors. У кеша появляются вопросы invalidation, TTL, размера и прав доступа. Во frontend memoization встречается в Angular |
Что такое dynamic programming на базовом уровне?
|
Dynamic programming разбивает задачу на пересекающиеся подзадачи и переиспользует их результаты. Обычно это memoization сверху вниз или табличное вычисление снизу вверх. Для Angular-разработчика важнее не заучивать академические задачи, а узнавать паттерн: если одно и то же производное значение пересчитывается много раз, можно сохранить результат по ключу. |
Что такое CPU cache и locality of reference?
|
CPU cache — быстрая память рядом с процессором. Она отличается от browser cache и HTTP cache: CPU cache ускоряет доступ к данным в памяти во время вычислений, а browser/HTTP cache уменьшает сетевые загрузки и чтение ресурсов. Locality of reference означает, что программа часто обращается к близким участкам памяти или повторно использует недавно прочитанные данные. Последовательный обход массива обычно дружелюбнее к CPU cache, чем хаотичные переходы по ссылкам. Во frontend это редко оптимизируют руками. Но понимание помогает объяснить, почему большие CPU-bound вычисления лучше измерять, упрощать алгоритмически, переносить в Web Worker или выполнять на сервере. |